向量的概念
关于“向量”,我已经在文章 R基础 中做了描述,这里再做些补充。
在 R 中,一般可以使用“数”的地方常常也可以使用“向量”,可以认为“向量”就是一种新的“数”, 把“向量”看成是“数”,这就是用好 R 的一个秘诀。
一个向量是有限多个同类元素(数)按顺序排成的,关键点是元素的类型、元素的个数和元素的顺序。 向量中的任何一个元素只是这个向量的一个分量。 正因为拥有着一串的数,向量具有着比单个数强大得多的描述事物的能力。
元素的类型决定了可以用在这个向量上的操作, 可以应用在一个向量的某个元素上的操作都可以应用到整个向量上。 如果需要把一个向量应用某种需要其它类型的操作, 在 R 中可能会使用隐含的类型转换机制先对向量的元素类型进行转换, 也有可能需要使用者明确地对向量进行类型转换后再来应用这一操作。
可以构造一个没有任何元素的向量,然后再给它添加元素,如下例所示:
> x <- vector()
> x
logical(0)
> mode(x)
[1] "logical"
> length(x)
[1] 0
> x[1] <- 1
> mode(x)
[1] "numeric"
> x
[1] 1
> x[10] <- 10
> x
[1] 1 NA NA NA NA NA NA NA NA 10
>
也可以一开始就明确向量的元素类型来创建一个空的向量,然后再添加元素:
> y <- vector(mode='numeric')
> y
numeric(0)
> length(y)
[1] 0
> class(x)
[1] "numeric"
> y[1] <- TRUE
> y
[1] 1
> mode(y)
[1] "numeric"
> y
[1] 1
>
通过 length() 来获得向量的元素个数,也即向量的长度。即使向量中如果有位置为Nan,它也被看是成同类的元素, 所以上述的向量 x 的长度为 10。
可以使用 is.vector() 来判断一个对象是否为向量, 可以使用 as.vector() 来把一个对象转换成向量。
可以使用 c() 来按枚举的方法构造向量, 可以使用 a:b、seq()、rep()等方法来构造元素符合序列、重复等规律的向量, 可以使用 scan() 从文件或者标准输入中依次添加元素的方式来构造向量, 可以通过对一个已知向量进行元素筛选、重新排列等方式来构造新向量, 可以通过已知向量之间的运算来构造新向量, 可以对矩阵或数阵等多维数据进行元素的选取或某种降维操作等来获得新的向量。
注意两个向量之间的比较:
> x <- 1:10
> y <- 11:20 - 10
> x
[1] 1 2 3 4 5 6 7 8 9 10
> y
[1] 1 2 3 4 5 6 7 8 9 10
> x == y
[1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
> all.equal(x, y)
[1] TRUE
> identical(x, y)
[1] FALSE
>
向量的一些常用工具
length() 得到向量长度(元素的个数)。
> x <- round(rnorm(10) * 10)
> x
[1] 9 12 12 -10 -5 -3 2 -12 5 1
> length(x)
[1] 10
names() 得到向量的名字向量,即向量中各元素的名字所在的向量,可以通过改变这个向量来对向量中的元素命名。
> names(x)
NULL
> names(x) <- 1:10
> names(x)
[1] "1" "2" "3" "4" "5" "6" "7" "8" "9" "10"
sort() 对向量的元素进行排序,可按升序或降序排列,默认为升序排列。
> sort(x)
8 4 5 6 10 7 9 1 2 3
-12 -10 -5 -3 1 2 5 9 12 12
> sort(x, decreasing=TRUE)
2 3 1 9 7 10 6 5 4 8
12 12 9 5 2 1 -3 -5 -10 -12
> sort(x, index.return=TRUE)
$x
8 4 5 6 10 7 9 1 2 3
-12 -10 -5 -3 1 2 5 9 12 12
$ix
[1] 8 4 5 6 10 7 9 1 2 3
rev() 把向量中的元素顺序颠倒,最前面的排到最后,最后面的排到最前。
> rev(x)
10 9 8 7 6 5 4 3 2 1
1 5 -12 2 -3 -5 -10 12 12 9
order() 获得排序后的元素所在原向量中的位置,相当于 sort(x,
index.return=TRUE)$ix,在这个例子中因为一开始就把元素的位置对元素进行了命名,所
以 order() 的结果就相当于 sort() 得到的向量的名字向量。
> order(x)
[1] 8 4 5 6 10 7 9 1 2 3
> names(sort(x))
[1] "8" "4" "5" "6" "10" "7" "9" "1" "2" "3"
> as.integer(names(sort(x)))
[1] 8 4 5 6 10 7 9 1 2 3
> sort(x, index.return=TRUE)$ix
[1] 8 4 5 6 10 7 9 1 2 3
按 order() 的结果来从原向量中可以选取出元素得到排序后的向量。
> x[order(x)]
8 4 5 6 10 7 9 1 2 3
-12 -10 -5 -3 1 2 5 9 12 12
rank() 对向量中的元素进行排名,并在原向量的每个元素的对应位置上给出元素的名次
,默认是按从小到大排名的。如果有重复的元素,则在一个名次上由多个元素来均摊,所
以会有浮点数出现。
> rank(x)
1 2 3 4 5 6 7 8 9 10
8.0 9.5 9.5 2.0 3.0 4.0 6.0 1.0 7.0 5.0
从排名的结果可以看出,原向量中第8个元素排第1名,也就是它是最小值。另外注意到第2 、3个元素的排名值出现了小数部分,原本应该一个排9,一个排10,但两个元素的值相同 ,所以平分了从9到10之间的名次。
unique() 去掉向量中的重复值,如果向量中有重复值时去掉重复值后,新向量的长度会
变短,元素的名字也会被忽略。
> unique(x)
[1] 9 12 -10 -5 -3 2 -12 5 1
duplicated() 检查向量中的每个元素,看看是否之前已经有出现过,如果出现过就为
TRUE,否则为 FALSE。可以用它来选出向量中重复的元素。
> duplicated(x)
[1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
> x[duplicated(x)]
3
12
从上面的结果知第3号元素在之前已经出现过了,有重复。
cut()把向量分成等间距的组,并为每个元素指定一个组索引。
> cut(x,3)
[1] (4,12] (4,12] (4,12] (-12,-4] (-12,-4] (-4,4] (-4,4] (-12,-4]
[9] (4,12] (-4,4]
Levels: (-12,-4] (-4,4] (4,12]
stem() 为向量生成 stem-and-leaf 图,这种图是一个用文本字符表示的可获得直观分
布形状的统计图。当可以使用图形表示时最好使用 hist() 或 density(),所以它的用武
之地越来越少了。
> stem(rnorm(100))
The decimal point is at the |
-2 | 75410
-1 | 97765432210000
-0 | 9999888777665433333222111
0 | 012222223333344444444455566677778899999
1 | 0011222225777789
2 | 6
把向量描绘成曲线
可以使用一个向量来表示一条曲线,并且可以绘制出它的近似图形。 例如用向量来近似表示一条悬链线,并画出来:
a <- 15
x <- seq(-5, 5, length=50)
y <- a * cosh(x/a) - a
plot(y, type='l')
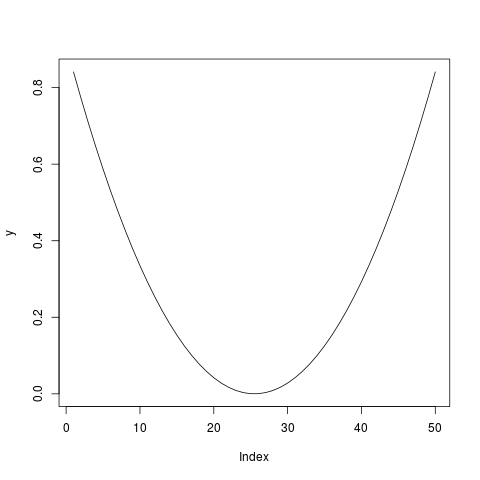 用向量表示近似的悬链线
用向量表示近似的悬链线
如果使用两个向量来配合,一个表示横坐标,另一个表示纵坐标,可以画出更复杂的曲线, 例如迪卡尔心形线:
th <- seq(0, 2*pi, length=100)
rho <- 1 - sin(th)
x <- rho * cos(th)
y <- rho * sin(th)
plot(y ~ x, type='l', col='red')
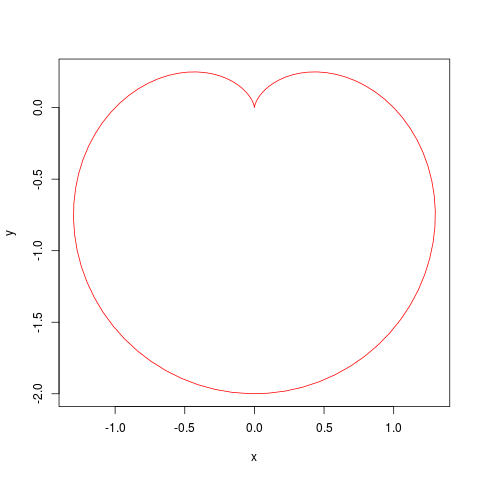 用两个向量画出来的近似迪卡尔心形线
用两个向量画出来的近似迪卡尔心形线