数据帧(data.frame)是 R 中的一类非常重要的特殊列表, 可以对同一件物体进行多次观察,每次从不同角度用数据来量化某个特定的属性, 把每个属性的数据做成描述这个属性的向量, 这一组向量放在一起就可以构成一个数据帧。
数据帧不仅仅用来描述一个物体,还能用来描述多个物体。 在 R 中存在大量函数来处理数据帧。
数据帧看起来有点向矩阵,它的每个元素都是一个长度相同的向量,可以看成是矩阵的列向量, 这些向量的长度是数据帧的行数,数据帧的向量一般通过列表元素的名字来访问; 每个向量中相同位置(相同行)的元素也都拥有相同的名字,这些名字是数据帧的行名字(row.names)。 数据帧的各个向量允许拥有不同的内容数据类型。
数据帧的向量可以按列表的方式来访问,另外还有一种特殊的元素选择方式是普通列表所不具有的, 数据帧允许按行来取元素,也可以同时按列和行来取元素,得到一个新的数据帧:
> dat <- data.frame(a=rep(1,9), b=1:9, c=(1:9)^2, d=(1:9)^3, e=(1:9)^4)
> dat
a b c d e
1 1 1 1 1 1
2 1 2 4 8 16
3 1 3 9 27 81
4 1 4 16 64 256
5 1 5 25 125 625
6 1 6 36 216 1296
7 1 7 49 343 2401
8 1 8 64 512 4096
9 1 9 81 729 6561
> dat[1:3] # 按列取
a b c
1 1 1 1
2 1 2 4
3 1 3 9
4 1 4 16
5 1 5 25
6 1 6 36
7 1 7 49
8 1 8 64
9 1 9 81
> dat[,1:3] # 还是按列取
a b c
1 1 1 1
2 1 2 4
3 1 3 9
4 1 4 16
5 1 5 25
6 1 6 36
7 1 7 49
8 1 8 64
9 1 9 81
> dat[1:3,] # 按行取
a b c d e
1 1 1 1 1 1
2 1 2 4 8 16
3 1 3 9 27 81
> dat[c(1,3,5:8),c('a','c','d')] # 按行、列取
a c d
1 1 1 1
3 1 9 27
5 1 25 125
6 1 36 216
7 1 49 343
8 1 64 512
>
从文本文件中读入数据帧到 R 中是非常方便的。 首先把需要处理的数据整理成一个如下格式的文本文件:
# file: my.dat
pc num cpu gam
A 1 26 36
B 1 26 35
C 1 26 36
D 1 26 31
E 1 26 38
A 2 52 35
B 2 52 51
C 2 52 42
D 2 52 40
E 2 51 33
A 3 77 45
B 3 77 78
C 3 77 62
D 3 76 46
E 3 76 44
A 4 99 60
C 4 99 86
D 4 96 59
E 4 99 57
这组数据是是我的某款服务程序在A、B、C、D、E等不同型号的计算机上的性能测试数据, num表示正在提供服务的数量,cpu表示消耗的cpu运算量百分数,gam表示消耗的gpu运算量百分数。 使用如下的命令可以把这组数据读入 R 中做成数据帧:
dat <- read.table('my.dat', header=TRUE)
这时的第一列也就是 dat$pc 是一个分类因子(factor)。 在 R 中,分类因子是一种特殊的向量,通过 read.table() 读入数据帧时, 当遇到字符型的向量时会自动将其转换成分类因子。
从数据表格中一时难以看到这帧数据所描述的事情的特征,如果将它们进行可视化处理, 这个特征就非常明显了。 在 R 中可以方便地绘制出这个数据帧中的 cpu 和 gpu 曲线簇:
require(lattice)
xyplot(cpu ~ num, dat, groups=pc, type='b', auto.key=list(space='right'))
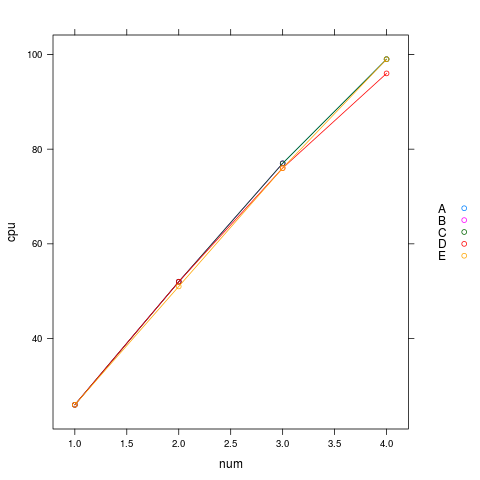 数据帧:某程序的cpu消耗曲线
数据帧:某程序的cpu消耗曲线
xyplot(gam ~ num, dat, groups=pc, type='b', auto.key=list(space='right'))
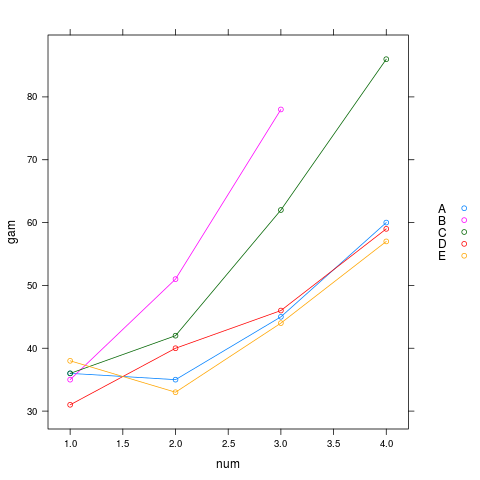 数据帧:某程序的gpu消耗曲线
数据帧:某程序的gpu消耗曲线
从这个数据帧绘制出的图形轻易就能看出,这个服务程序对 cpu 和 gpu 的消耗都具有线性特征, 并且在这几款已测机型上,服务程序的cpu消耗速度一样但gpu消耗速度不同。 机型A、D、E上的gpu消耗速度大致相当,而B机型的gpu消耗速度过快以致不能支持数量为4的服务。